The New Default. Your hub for building smart, fast, and sustainable AI software

Table of Contents
Executive summary
For most teams, the best return comes from starting with retrieval-augmented generation (RAG) and adding fine-tuning only where a narrow task or a fixed house style demands it.
RAG is cheaper to launch, keeps answers current, and can cite its sources, which covers the bulk of business use cases: support, document search, and internal Q&A. Fine-tuning earns its higher cost when you need consistent behavior or a specialized task and your underlying data rarely changes.
The two are complementary, and mature systems usually combine them. The real ROI lever is not the technique you pick; it is how well you build the data pipeline underneath it.
You've approved the budget for your AI solution, the use case is real, and your proprietary data (contracts, support tickets, product manuals, years of institutional knowledge) is finally going to earn its keep.
Then you hit the first genuinely technical fork in the road.
One camp says retrieval-augmented generation (RAG). The other says fine-tuning.
Both promise to make a large language model (LLM) useful on your data, both have credible advocates and case studies, and both can burn through your budget if you choose for the wrong reason.
Most teams frame this as a contest between two techniques. The more useful question is about your own data: do you want to change what the model knows, or what it is?
RAG changes what it knows. Fine-tuning changes what it is. Once you can answer that, the ROI decision mostly follows.
What Problems Do RAG and Fine-Tuning Solve?
Out of the box, even the best LLM knows nothing about your business. It was trained on a vast slice of the public internet, frozen at some point in the past. It has never seen your pricing rules, your compliance policies, or last quarter's board deck.
The dangerous part is that it won't tell you that. Ask a base model a question about your internal data and it rarely says "I don't know." Instead it produces a fluent, confident, and entirely invented answer.
The industry politely calls this hallucination. As IBM notes, models without access to relevant data "make up answers to questions they cannot definitively answer." Catastrophic when the answer drives a customer decision or a regulatory filing.
RAG and fine-tuning are two answers to this single gap. RAG gives the model access to your knowledge at the moment it answers. Fine-tuning changes the model itself. That distinction does most of the work in this decision.
What Makes RAG Work?
Retrieval-augmented generation, the technique introduced by Meta researchers in a 2020 paper, works like an open-book exam.
When a user asks a question, the the system first searches your data for the most relevant passages, hands those passages to the model along with the question, and only then asks it to answer.
The model is reading from your sources in real time, no memory involved.
IBM frames the base model as a competent home cook who knows general technique but not your cuisine. RAG hands that cook your cookbook, so they can produce your specific dishes on demand.
Two consequences matter for ROI.
First, the model can cite its sources, so a user or an auditor can follow the trail back to the original document, a point Cohere highlights as central to trust and compliance.
Second, your knowledge lives in a database outside the model. Update a policy, add a contract, retire an old FAQ, and the system reflects the change immediately, with no retraining required. For any business whose information moves, that is the headline benefit.
But RAG is only as good as its plumbing.
The quality of every answer depends on how well you parse, chunk, and index your documents before the model ever sees them. Mangle that pipeline and no clever model will rescue you.
What Makes Fine-Tuning Work?
Fine-tuning is the closed-book exam. Instead of looking information up at question time, you retrain the model on a curated set of examples so that the desired knowledge, tone, or behavior is baked into its weights. In the cooking analogy, IBM describes this as sending the cook to a course in a specific cuisine, after which they simply are a specialist.
This is where fine-tuning shines: consistency. If you need every output in a precise house style, every classification to follow your taxonomy, or a model that reliably performs a narrow task like summarization or sentiment analysis, fine-tuning delivers a depth of specialization that prompting alone struggles to match.
Modern fine-tuning is also cheaper than it used to be. Rather than updating every parameter, parameter-efficient fine-tuning (PEFT), including popular methods like LoRA, adjusts only the most relevant ones. As IBM explains, this keeps training costs down while delivering comparable gains.
But fine-tuning has an Achilles' heel that decision-makers consistently underestimate: knowledge goes stale. Once your contracts or policies change, the model still confidently answers using the old information frozen in its weights. As one practitioner bluntly puts it, you've traded "making things up" for "confidently wrong about stale data." The only fix is to retrain, again and again, every time reality moves.
Why Is It Risky To "Just Use a Giant Context Window"?
You've probably heard the counterargument: context windows are now enormous, so why bother with retrieval? Just paste everything into the prompt. Every few months, someone declares "RAG is dead" on exactly this logic.
It's a seductive argument and a costly trap. The flaw is confusing capacity with findability. Your email inbox can hold 50,000 messages, but you would never read all of them to find one. You would search. A million-token window means you can fit more documents; it says nothing about whether the model can find the right sentence inside them.
The research points the other way. The well-documented "lost in the middle" effect shows that models pay most attention to the start and end of a long context and neglect the middle. More recently, Chroma's "context rot" study tested 18 frontier models, including Anthropic's Claude 4, OpenAI's GPT-4.1, Google's Gemini 2.5, and Alibaba's Qwen3. Every one of them got less reliable as input grew, even on simple retrieval tasks, and well before the context window was full. Adding loosely relevant text didn't just waste space; it degraded accuracy.
So the conclusion flips the "RAG is dead" claim around. Bigger context windows make retrieval quality more important, not less. Feed a capable model the right ten pages and it excels; bury it in a loosely relevant hundred and it founders. Context windows decide how much you can fit; retrieval decides whether the model actually finds what matters.
What Is The ROI of RAG Compared To Fine-Tuning?
Here is how the two approaches compare on the dimensions a budget owner cares about. Treat the cost and timeline figures as directional industry estimates rather than quotes; your numbers will depend on data volume, model choice, and scope.
Dimension | RAG | Fine-tuning |
|---|---|---|
Time to first value | Weeks | Months |
Upfront cost | Lower: no model training | Higher: data prep plus GPU compute |
Keeping data current | Update the database anytime | Retrain to refresh knowledge |
Source citations / auditability | Native: answers link to sources | Not inherent |
Consistent tone & behavior | Limited | Strong |
Main ongoing risk | Retrieval latency; pipeline quality | Stale knowledge; overfitting |
The pattern across industry analyses is consistent. RAG generally reaches production faster and cheaper because there is no training step; practitioners describe RAG systems deploying in weeks rather than the months a fine-tuning project can require. Fine-tuning costs vary enormously. An efficient PEFT/LoRA run on a small model can cost a few hundred dollars, while a full fine-tune of a large model can run into the tens of thousands per run, and you may need several runs to get it right.
The biggest hidden cost of fine-tuning shows up after the first training run. If your data changes quarterly, you are either retraining on that cadence or living with answers that drift out of date. RAG sidesteps this by keeping knowledge outside the model. Its own trade-offs are real but different: some added latency, since it must retrieve before it generates, and a heavy dependence on the quality of the ingestion pipeline. AWS's guidance reflects the same balance. Its prescriptive recommendation is to start from RAG for document question-answering and reach for fine-tuning when you need the model to perform additional tasks.
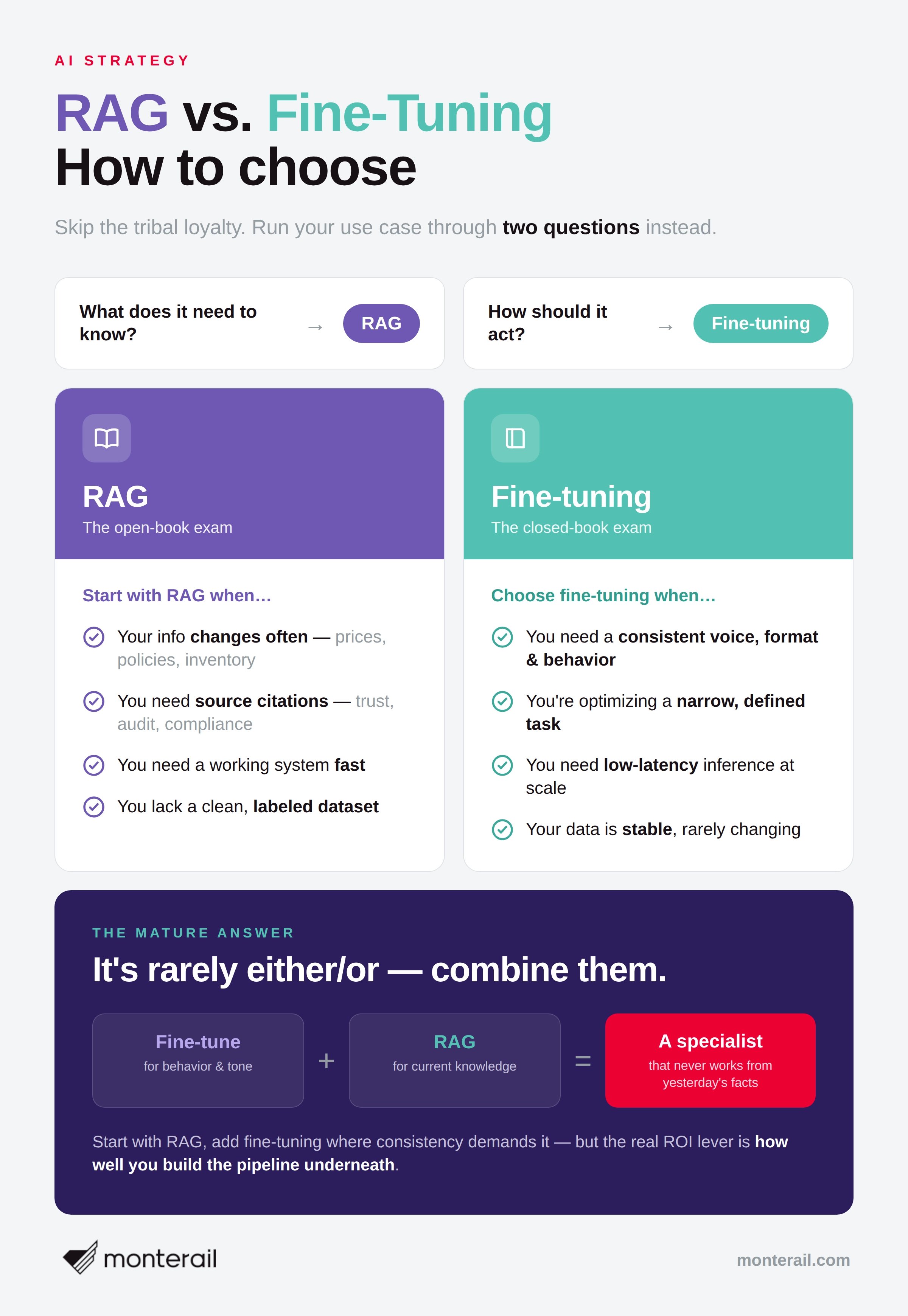
How To Choose Between RAG and Fine-Tuning Based On
Skip the tribal loyalty and run your use case through two questions instead.
Start with RAG when
Your information changes often: prices, policies, inventory, regulations.
You need source citations for trust, auditing, or compliance.
You need a working system fast, without a long data-labeling project.
You don't have a large, clean, labeled dataset to train on.
This covers the majority of business cases people actually have in mind: internal knowledge search, customer support, document Q&A, and research assistants. It's no accident that AWS recommends RAG as the default starting point for these.
Choose fine-tuning when
You need a consistent voice, format, or behavior across every output.
You're optimizing a narrow, well-defined task: classification, structured extraction, or summarization to a fixed template.
You need low-latency inference at scale, with no retrieval step in the loop.
Your data is stable and unlikely to change often.
Cohere's framing is a useful shorthand: RAG gives the model up-to-date knowledge; fine-tuning shapes its behavior. Most of the time, "what does it need to know?" points you to RAG and "how should it act?" points you to fine-tuning.
One rule matters most: this is rarely a permanent either/or. The real choice is about sequence and proportion, which points to the answer mature teams usually land on.
When To Combine RAG and Fine-Tuning
Treat the two methods as complements rather than rivals. Fine-tune a model so it behaves the way you need, in your tone, your format, and your task, then wrap it in RAG so it always answers from current, citable knowledge. The result is a specialist that never works from yesterday's facts.
Research is already formalizing this. Berkeley's RAFT (Retrieval-Augmented Fine-Tuning) trains a model specifically to be better at using retrieved documents: the open-book exam, but for a student who also studied. AWS likewise notes you can fine-tune the generating model inside a RAG architecture to get the best of both. The industry is moving further still, toward agentic RAG, where models don't just retrieve once but reason, plan, and pull information across multiple steps. The momentum is real: Gartner projects that 40% of enterprise applications will include task-specific AI agents by the end of 2026, up from less than 5% in 2025.
You probably don't need all of this on day one. Knowing it exists keeps you from over-investing in a closed-book model when your real destination is a system that both knows and behaves.
How Should You Decide Between RAG and Fine-Tuning?
Treat this as a systems decision, not a technology bake-off: the best ROI comes from matching the method to how your data behaves, then doing the unglamorous work of building the pipeline well.
For most teams that means starting with RAG, adding fine-tuning where consistency or a specialized task demands it, and combining the two as the use case matures.
The pipeline is where projects succeed or fail. The careful data preparation, the retrieval quality, the security and compliance guardrails. That is the part the "RAG vs. fine-tuning" debate tends to skip.
At Monterail, we build secure, source-cited AI systems on our clients' own data, and we choose the approach that fits the problem rather than the other way around. If you're weighing this decision for a real project, we're happy to talk it through.
Key takeaways
For most business use cases, RAG is the cheaper, faster place to start, and it keeps answers current without retraining.
Fine-tuning earns its higher cost when you need consistent behavior or a narrow, well-defined task and your data rarely changes.
A bigger context window is not a substitute for retrieval. Accuracy drops as input grows, so finding the right passage still matters.
Stale knowledge is fine-tuning's recurring hidden cost. Budget for retraining, or expect answers to drift.
The strongest systems combine both: fine-tune for behavior, retrieve for knowledge.
RAG and Fine-Tuning FAQ
)
Michał Nowakowski
Solution Architect and AI Expert at Monterail
Michał Nowakowski is a Solution Architect and AI Expert at Monterail. His strong data and automation foundation and background in operational business units give him a real-world understanding of company challenges. Michał leads feature discovery and business process design to surface hidden value and identify new verticals. He also advocates for AI-assisted development, skillfully integrating strict conditional logic with open-weight machine learning capabilities to build systems that reduce manual effort and unlock overlooked opportunities.